Comparing a knowledge-driven approach to a supervised machine learning approach in large-scale extraction of drug-side effect relationships from free-text biomedical literature
Supporting Files

-
Mar 18 2015
-
Details
-
Alternative Title:BMC Bioinformatics
-
Personal Author:
-
Description:Background
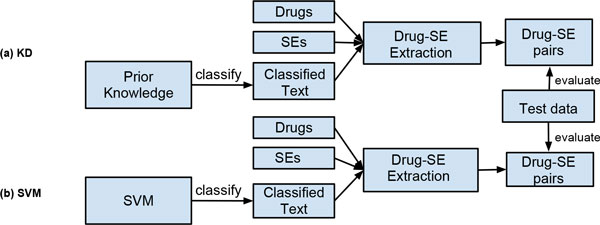
Systems approaches to studying drug-side-effect (drug-SE) associations are emerging as an active research area for both drug target discovery and drug repositioning. However, a comprehensive drug-SE association knowledge base does not exist. In this study, we present a novel knowledge-driven (KD) approach to effectively extract a large number of drug-SE pairs from published biomedical literature.
Data and methods
For the text corpus, we used 21,354,075 MEDLINE records (119,085,682 sentences). First, we used known drug-SE associations derived from FDA drug labels as prior knowledge to automatically find SE-related sentences and abstracts. We then extracted a total of 49,575 drug-SE pairs from MEDLINE sentences and 180,454 pairs from abstracts.
Results
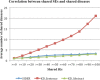
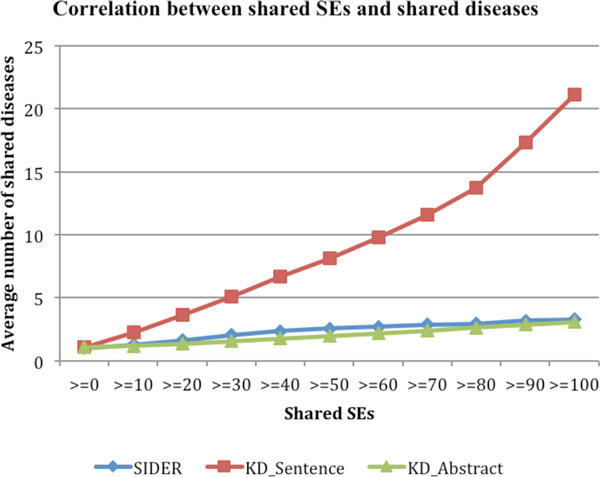
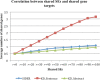
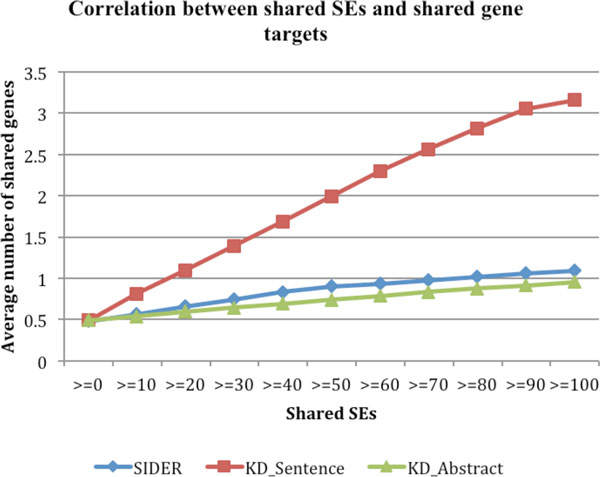
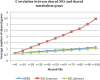
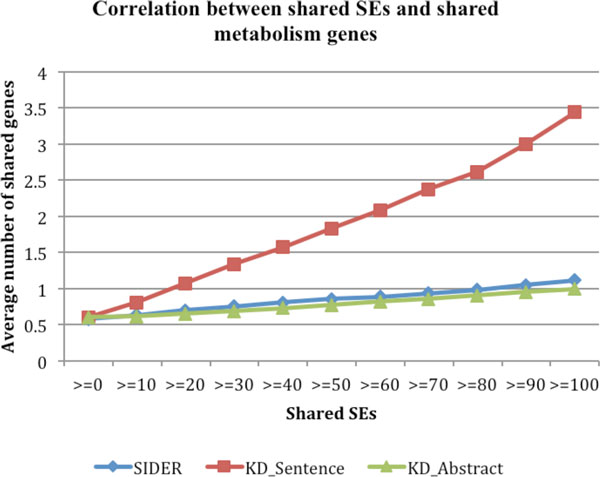
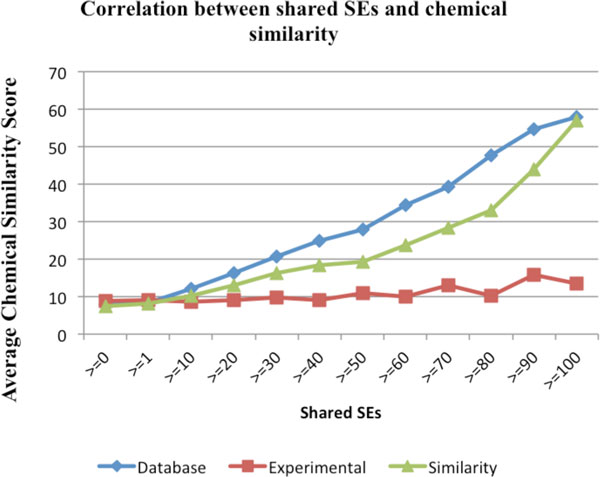
On average, the KD approach has achieved a precision of 0.335, a recall of 0.509, and an F1 of 0.392, which is significantly better than a SVM-based machine learning approach (precision: 0.135, recall: 0.900, F1: 0.233) with a 73.0% increase in F1 score. Through integrative analysis, we demonstrate that the higher-level phenotypic drug-SE relationships reflects lower-level genetic, genomic, and chemical drug mechanisms. In addition, we show that the extracted drug-SE pairs can be directly used in drug repositioning.
Conclusion
In summary, we automatically constructed a large-scale higher-level drug phenotype relationship knowledge, which can have great potential in computational drug discovery.
-
Subjects:
-
Source:BMC Bioinformatics. 2015; 16(Suppl 5):S6.
-
Pubmed ID:25860223
-
Pubmed Central ID:PMC4402591
-
Document Type:
-
Funding:
-
Volume:16
-
Collection(s):
-
Main Document Checksum:urn:sha256:3fc793282441666ee1120a7aa177fed664d9e986c25634847cbc31640861fa02
-
Download URL:
-
File Type:
 [PDF
- 1.01 MB
]
[PDF
- 1.01 MB
]
Supporting Files

ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access