Large-scale automatic extraction of side effects associated with targeted anticancer drugs from full-text oncological articles
Supporting Files

-
Mar 27 2015
-
Details
-
Alternative Title:J Biomed Inform
-
Personal Author:
-
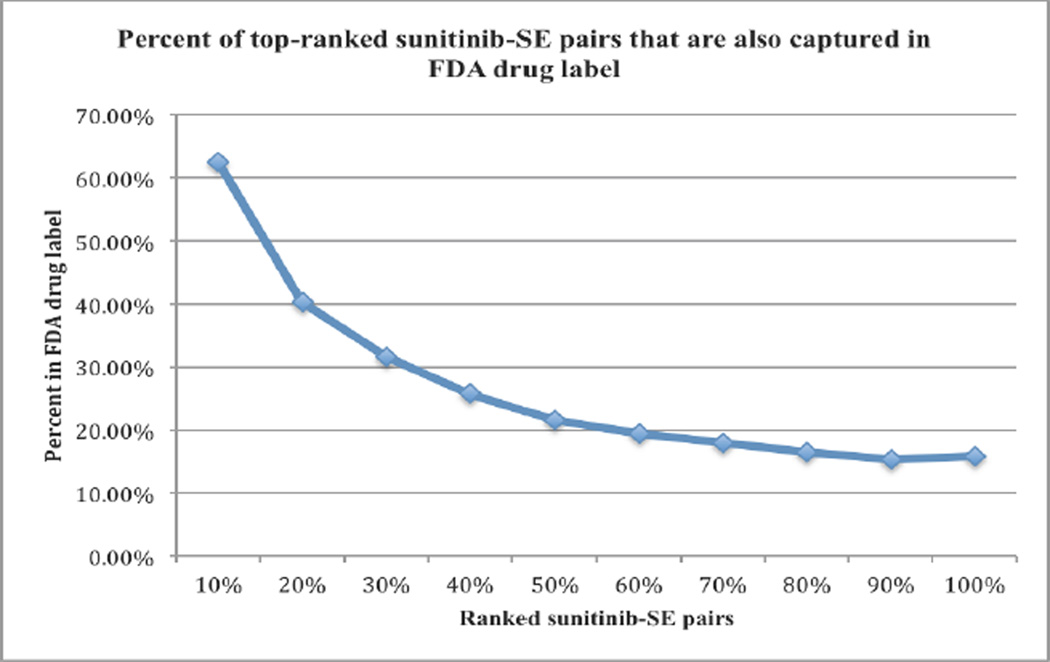
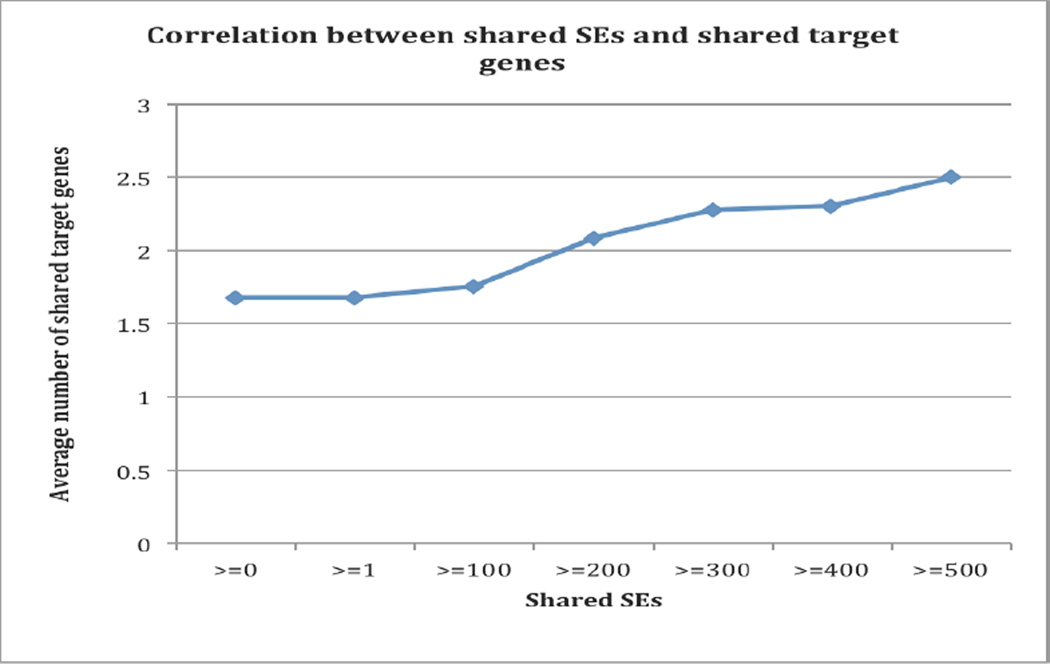
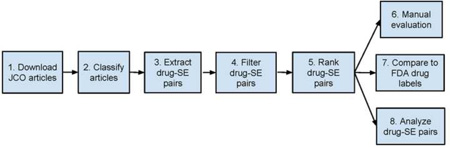
Description:Targeted anticancer drugs such as imatinib, trastuzumab and erlotinib dramatically improved treatment outcomes in cancer patients, however, these innovative agents are often associated with unexpected side effects. The pathophysiological mechanisms underlying these side effects are not well understood. The availability of a comprehensive knowledge base of side effects associated with targeted anticancer drugs has the potential to illuminate complex pathways underlying toxicities induced by these innovative drugs. While side effect association knowledge for targeted drugs exists in multiple heterogeneous data sources, published full-text oncological articles represent an important source of pivotal, investigational, and even failed trials in a variety of patient populations. In this study, we present an automatic process to extract targeted anticancer drug-associated side effects (drug-SE pairs) from a large number of high profile full-text oncological articles. We downloaded 13,855 full-text articles from the Journal of Oncology (JCO) published between 1983 and 2013. We developed text classification, relationship extraction, signaling filtering, and signal prioritization algorithms to extract drug-SE pairs from downloaded articles. We extracted a total of 26,264 drug-SE pairs with an average precision of 0.405, a recall of 0.899, and an F1 score of 0.465. We show that side effect knowledge from JCO articles is largely complementary to that from the US Food and Drug Administration (FDA) drug labels. Through integrative correlation analysis, we show that targeted drug-associated side effects positively correlate with their gene targets and disease indications. In conclusion, this unique database that we built from a large number of high-profile oncological articles could facilitate the development of computational models to understand toxic effects associated with targeted anticancer drugs.
-
Subjects:
-
Source:J Biomed Inform. 55:64-72.
-
Pubmed ID:25817969
-
Pubmed Central ID:PMC4582661
-
Document Type:
-
Funding:
-
Volume:55
-
Collection(s):
-
Main Document Checksum:urn:sha256:835072704dd9c77685f9af070af73a8e4977e6d737ae31c9ae5c47b9d049398e
-
Download URL:
-
File Type:
 [PDF
- 1.19 MB
]
[PDF
- 1.19 MB
]
Supporting Files

ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access