fast_protein_cluster: parallel and optimized clustering of large-scale protein modeling data
Supporting Files

-
Feb 14 2014
Details
-
Alternative Title:Bioinformatics
-
Personal Author:
-
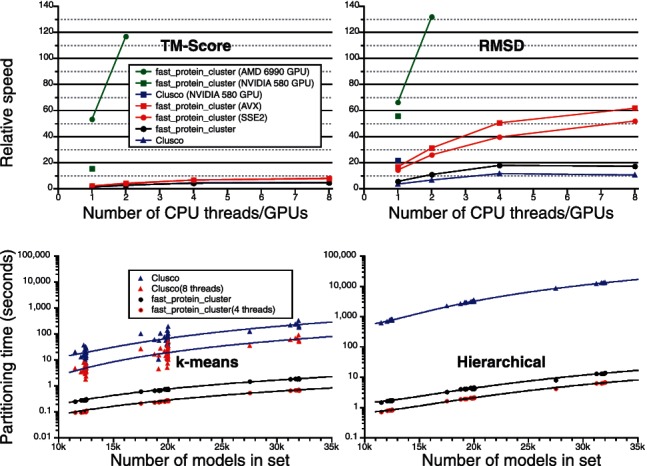
Description:fast_protein_cluster is a fast, parallel and memory efficient package used to cluster 60 000 sets of protein models (with up to 550 000 models per set) generated by the Nutritious Rice for the World project.|fast_protein_cluster is an optimized and extensible toolkit that supports Root Mean Square Deviation after optimal superposition (RMSD) and Template Modeling score (TM-score) as metrics. RMSD calculations using a laptop CPU are 60× faster than qcprot and 3× faster than current graphics processing unit (GPU) implementations. New GPU code further increases the speed of RMSD and TM-score calculations. fast_protein_cluster provides novel k-means and hierarchical clustering methods that are up to 250× and 2000× faster, respectively, than Clusco, and identify significantly more accurate models than Spicker and Clusco.|fast_protein_cluster is written in C++ using OpenMP for multi-threading support. Custom streaming Single Instruction Multiple Data (SIMD) extensions and advanced vector extension intrinsics code accelerate CPU calculations, and OpenCL kernels support AMD and Nvidia GPUs. fast_protein_cluster is available under the M.I.T. license. (http://software.compbio.washington.edu/fast_protein_cluster)
-
Subjects:
-
Source:Bioinformatics. 2014; 30(12):1774-1776.
-
Pubmed ID:24532722
-
Pubmed Central ID:PMC4058946
-
Document Type:
-
Funding:
-
Volume:30
-
Issue:12
-
Collection(s):
-
Main Document Checksum:urn:sha256:125a233bf96c69377eefd9b19c7b4b1d79abd74890f9b0f009ef8b8dbc233c79
-
Download URL:
-
File Type:
 [PDF
- 165.72 KB
]
[PDF
- 165.72 KB
]
Supporting Files

ON THIS PAGE

{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access