A Bayesian Approach for Summarizing and Modeling Time-Series Exposure Data with Left Censoring
Supporting Files

-
Aug 01 2017
File Language:
English
Details
-
Alternative Title:Ann Work Expo Health
-
Personal Author:
-
Description:Objective
Direct reading instruments are valuable tools for measuring exposure as they provide real-time measurements for rapid decision making. However, their use is limited to general survey applications in part due to issues related to their performance. Moreover, statistical analysis of real-time data is complicated by autocorrelation among successive measurements, non-stationary time series, and the presence of left-censoring due to limit-of-detection (LOD). A Bayesian framework is proposed that accounts for non-stationary autocorrelation and LOD issues in exposure time-series data in order to model workplace factors that affect exposure and estimate summary statistics for tasks or other covariates of interest.
Method
A spline-based approach is used to model non-stationary autocorrelation with relatively few assumptions about autocorrelation structure. Left-censoring is addressed by integrating over the left tail of the distribution. The model is fit using Markov-Chain Monte Carlo within a Bayesian paradigm. The method can flexibly account for hierarchical relationships, random effects and fixed effects of covariates. The method is implemented using the rjags package in R, and is illustrated by applying it to real-time exposure data. Estimates for task means and covariates from the Bayesian model are compared to those from conventional frequentist models including linear regression, mixed-effects, and time-series models with different autocorrelation structures. Simulations studies are also conducted to evaluate method performance.
Results
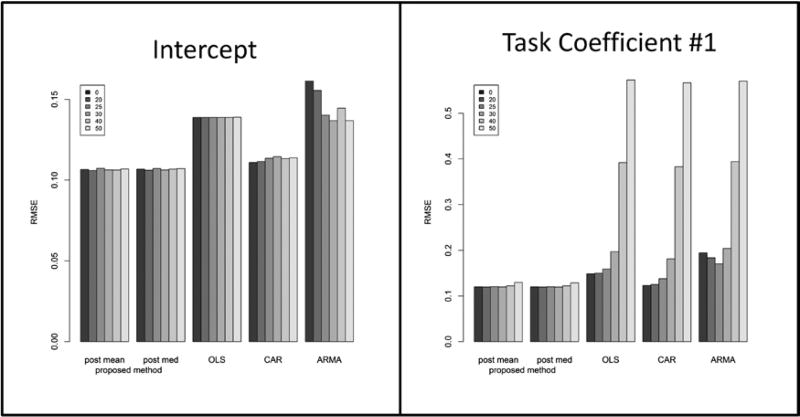
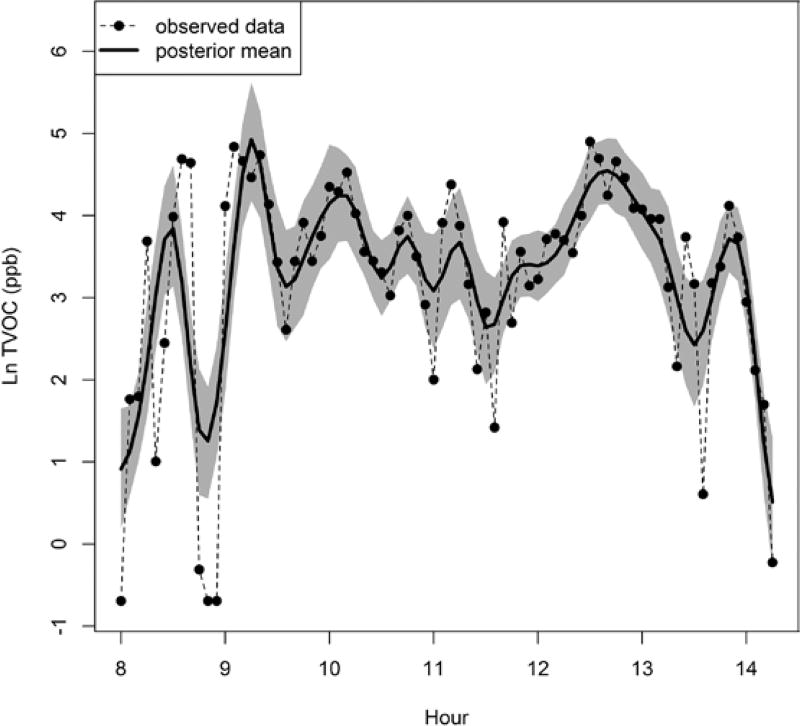
Simulation studies with percent of measurements below the LOD ranging from 0 to 50% showed lowest root mean squared errors for task means and the least biased standard deviations from the Bayesian model compared to the frequentist models across all levels of LOD. In the application, task means from the Bayesian model were similar to means from the frequentist models, while the standard deviations were different. Parameter estimates for covariates were significant in some frequentist models, but in the Bayesian model their credible intervals contained zero; such discrepancies were observed in multiple datasets. Variance components from the Bayesian model reflected substantial autocorrelation, consistent with the frequentist models, except for the auto-regressive moving average model. Plots of means from the Bayesian model showed good fit to the observed data.
Conclusion
The proposed Bayesian model provides an approach for modeling non-stationary autocorrelation in a hierarchical modeling framework to estimate task means, standard deviations, quantiles, and parameter estimates for covariates that are less biased and have better performance characteristics than some of the contemporary methods.
-
Subjects:
-
Source:Ann Work Expo Health. 61(7):773-783.
-
Pubmed ID:28810680
-
Pubmed Central ID:PMC5712446
-
Document Type:
-
Funding:
-
Volume:61
-
Issue:7
-
Collection(s):
-
Main Document Checksum:urn:sha256:4455fa966cb5b8e1b5d261d3fd822f0518fd42504bc8d9c2556a3f1e6c0a8afc
-
Download URL:
-
File Type:
 [PDF
- 2.03 MB
]
[PDF
- 2.03 MB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access