Evaluation of various distance computation methods for construction of haplotype-based phylogenies from large MLST datasets
Supporting Files

-
12 2022
-
File Language:
English
Details
-
Alternative Title:Mol Phylogenet Evol
-
Personal Author:
-
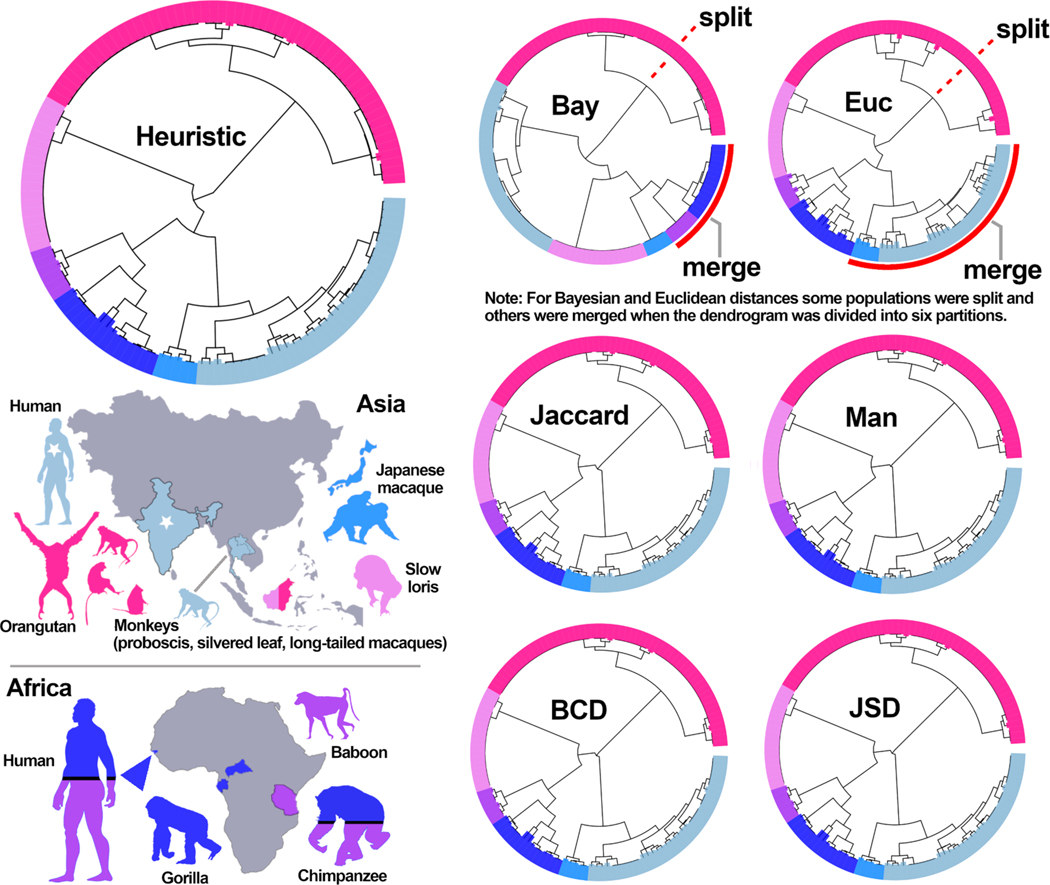
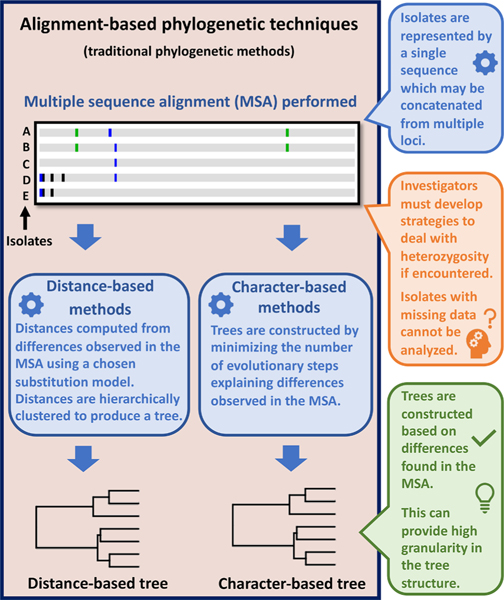
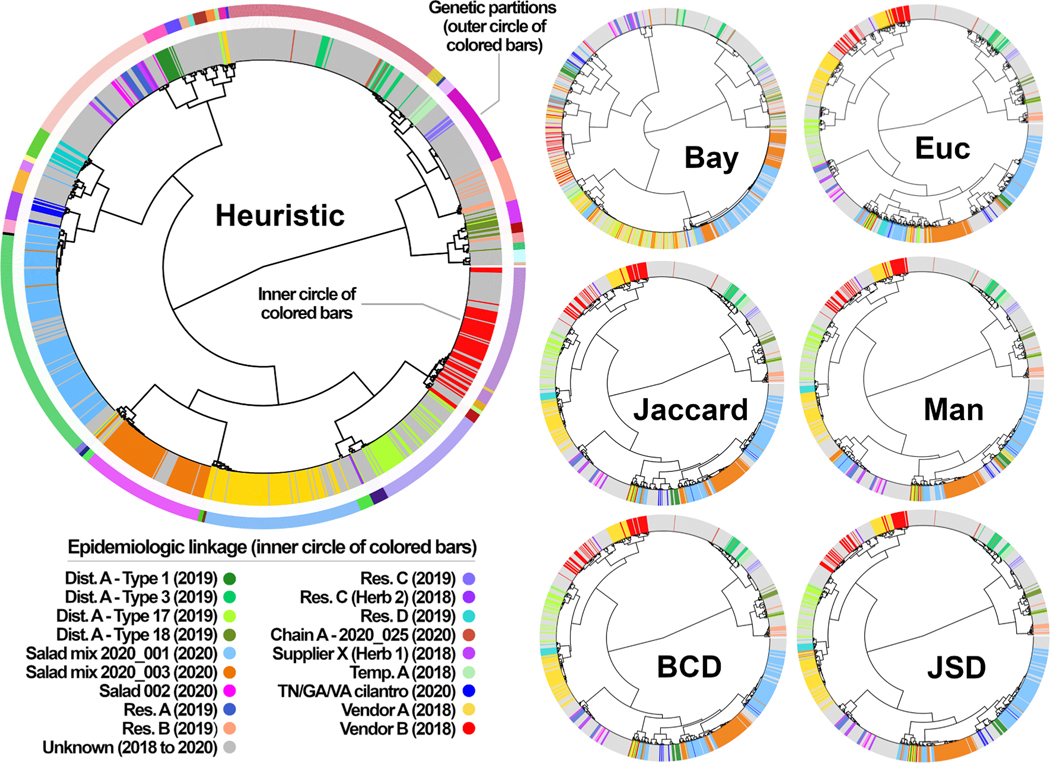
Description:Multi-locus sequence typing (MLST) is widely used to investigate genetic relationships among eukaryotic taxa, including parasitic pathogens. MLST analysis workflows typically involve construction of alignment-based phylogenetic trees - i.e., where tree structures are computed from nucleotide differences observed in a multiple sequence alignment (MSA). Notably, alignment-based phylogenetic methods require that all isolates/taxa are represented by a single sequence. When multiple loci are sequenced these sequences may be concatenated to produce one tree that includes information from all loci. Alignment-based phylogenetic techniques are robust and widely used yet possess some shortcomings, including how heterozygous sites are handled, intolerance for missing data (i.e., partial genotypes), and differences in the way insertions-deletions (indels) are scored/treated during tree construction. In certain contexts, 'haplotype-based' methods may represent a viable alternative to alignment-based techniques, as they do not possess the aforementioned limitations. This is namely because haplotype-based methods assess genetic similarity based on numbers of shared (i.e., intersecting) haplotypes as opposed to similarities in nucleotide composition observed in an MSA. For haplotype-based comparisons, choosing an appropriate distance statistic is fundamental, and several statistics are available to choose from. However, a comprehensive assessment of various available statistics for their ability to produce a robust haplotype-based phylogenetic reconstruction has not yet been performed. We evaluated seven distance statistics by applying them to extant MLST datasets from the gastrointestinal parasite Cyclospora cayetanensis and two species of pathogenic nematode of the genus Strongyloides. We compare the genetic relationships identified using each statistic to epidemiologic, geographic, and host metadata. We show that Barratt's heuristic definition of genetic distance was the most robust among the statistics evaluated. Consequently, it is proposed that Barratt's heuristic represents a useful approach for use in the context of challenging MLST datasets possessing features (i.e., high heterozygosity, partial genotypes, and indel or repeat-based polymorphisms) that confound or preclude the use of alignment-based methods.
-
Subjects:
-
Source:Mol Phylogenet Evol. 177:107608
-
Pubmed ID:35963590
-
Pubmed Central ID:PMC10127246
-
Document Type:
-
Funding:
-
Volume:177
-
Collection(s):
-
Main Document Checksum:urn:sha256:e8f251521c0357a87d145320549062506f92c53619f8db7472c5f6239ad0f246
-
Download URL:
-
File Type:
 [PDF
- 2.41 MB
]
[PDF
- 2.41 MB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access