A Note on the Effect of Data Clustering on the Multiple-Imputation Variance Estimator: A Theoretical Addendum to Lewis et al. (2014), JOS
Supporting Files

-
March 10 2016
-
File Language:
English
Details
-
Alternative Title:J Off Stat
-
Personal Author:
-
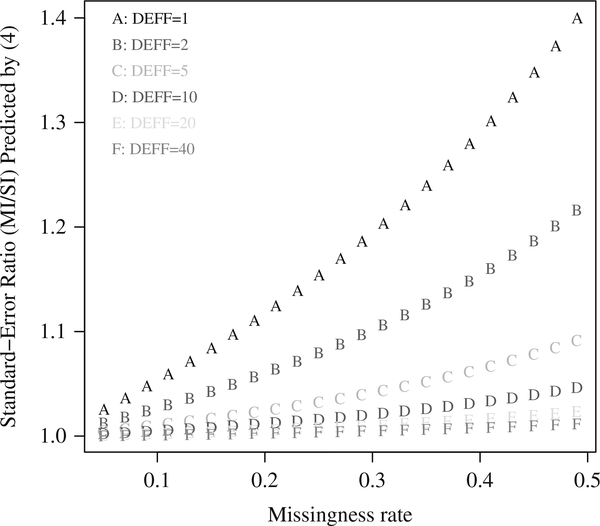
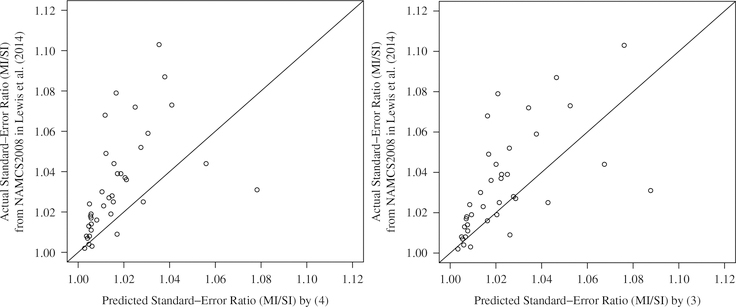
Description:Multiple imputation is a popular approach to handling missing data. Although it was originally motivated by survey nonresponse problems, it has been readily applied to other data settings. However, its general behavior still remains unclear when applied to survey data with complex sample designs, including clustering. Recently, Lewis et al. (2014) compared single- and multiple-imputation analyses for certain incomplete variables in the 2008 National Ambulatory Medicare Care Survey, which has a nationally representative, multistage, and clustered sampling design. Their study results suggested that the increase of the variance estimate due to multiple imputation compared with single imputation largely disappears for estimates with large design effects. We complement their empirical research by providing some theoretical reasoning. We consider data sampled from an equally weighted, single-stage cluster design and characterize the process using a balanced, one-way normal random-effects model. Assuming that the missingness is completely at random, we derive analytic expressions for the within- and between-multiple-imputation variance estimators for the mean estimator, and thus conveniently reveal the impact of design effects on these variance estimators. We propose approximations for the fraction of missing information in clustered samples, extending previous results for simple random samples. We discuss some generalizations of this research and its practical implications for data release by statistical agencies.
-
Subjects:
-
Source:J Off Stat. 32(1):147-164
-
Pubmed ID:30948863
-
Pubmed Central ID:PMC6444354
-
Document Type:
-
Funding:
-
Volume:32
-
Issue:1
-
Collection(s):
-
Main Document Checksum:urn:sha256:8e9c9146cbafbb2f00f40e615f8d86d59819925c6249e71f00f6b17e38842a77
-
Download URL:
-
File Type:
 [PDF
- 731.65 KB
]
[PDF
- 731.65 KB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access