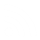i
Benchmark datasets for phylogenomic pipeline validation, applications for foodborne pathogen surveillance
-
Oct 06 2017
Source: PeerJ. 2017; 5 -
Alternative Title:PeerJ
-
Personal Author:
-
Description:Background
As next generation sequence technology has advanced, there have been parallel advances in genome-scale analysis programs for determining evolutionary relationships as proxies for epidemiological relationship in public health. Most new programs skip traditional steps of ortholog determination and multi-gene alignment, instead identifying variants across a set of genomes, then summarizing results in a matrix of single-nucleotide polymorphisms or alleles for standard phylogenetic analysis. However, public health authorities need to document the performance of these methods with appropriate and comprehensive datasets so they can be validated for specific purposes, e.g., outbreak surveillance. Here we propose a set of benchmark datasets to be used for comparison and validation of phylogenomic pipelines.
Methods
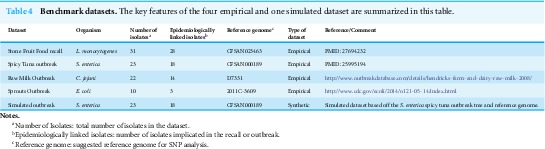
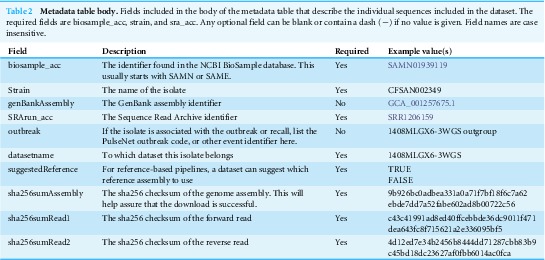
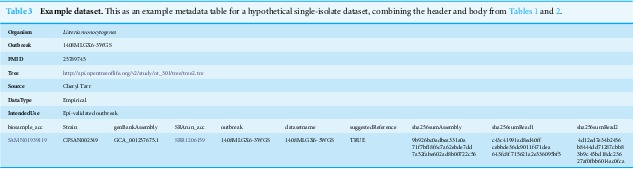
We identified four well-documented foodborne pathogen events in which the epidemiology was concordant with routine phylogenomic analyses (reference-based SNP and wgMLST approaches). These are ideal benchmark datasets, as the trees, WGS data, and epidemiological data for each are all in agreement. We have placed these sequence data, sample metadata, and “known” phylogenetic trees in publicly-accessible databases and developed a standard descriptive spreadsheet format describing each dataset. To facilitate easy downloading of these benchmarks, we developed an automated script that uses the standard descriptive spreadsheet format.
Results
Our “outbreak” benchmark datasets represent the four major foodborne bacterial pathogens (Listeria monocytogenes, Salmonella enterica, Escherichia coli, and Campylobacter jejuni) and one simulated dataset where the “known tree” can be accurately called the “true tree”. The downloading script and associated table files are available on GitHub: https://github.com/WGS-standards-and-analysis/datasets.
Discussion
These five benchmark datasets will help standardize comparison of current and future phylogenomic pipelines, and facilitate important cross-institutional collaborations. Our work is part of a global effort to provide collaborative infrastructure for sequence data and analytic tools—we welcome additional benchmark datasets in our recommended format, and, if relevant, we will add these on our GitHub site. Together, these datasets, dataset format, and the underlying GitHub infrastructure present a recommended path for worldwide standardization of phylogenomic pipelines.
-
Subjects:
-
Source:
-
Pubmed ID:29372115
-
Pubmed Central ID:PMC5782805
-
Document Type:
-
Collection(s):
-
Main Document Checksum:
-
Download URL:
-
File Type:
-

gif 
jpeg 
xlsx
xlsx
xlsx
xlsx
xlsx 
xml 
gif 
jpeg 
gif 
jpeg 
gif 
jpeg 
gif 
jpeg
 [PDF-1021.52 KB]
[PDF-1021.52 KB]
Details:
Supporting Files







More +


 Email
CDC-INFO
Email
CDC-INFO