Distinguishing petroleum (crude oil and fuel) from smoke exposure within populations based on the relative levels of benzene, toluene, ethylbenzene, and xylenes (BTEX), styrene and 2,5-dimethylfuran by pattern recognition using artificial neural networks
Supporting Files

-
Dec 19 2017
-
File Language:
English
Details
-
Alternative Title:Environ Sci Technol
-
Personal Author:
-
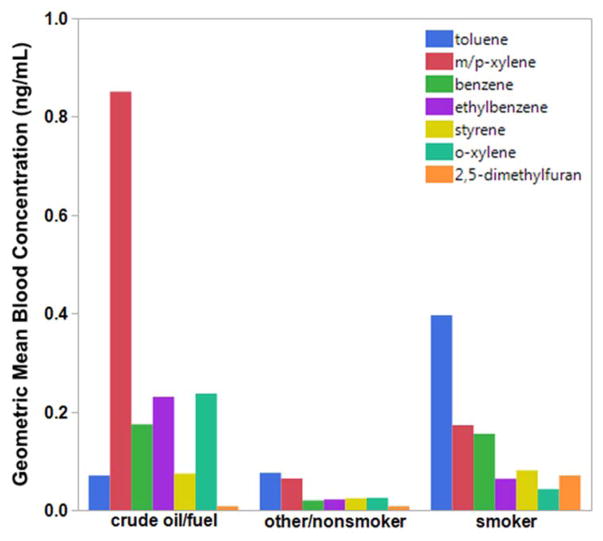
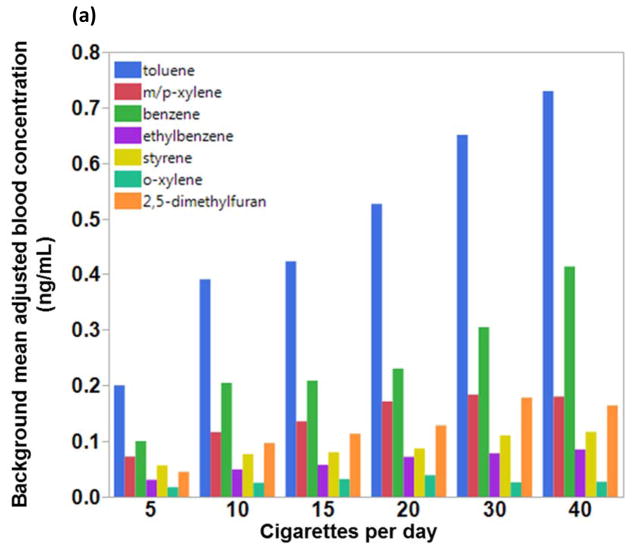
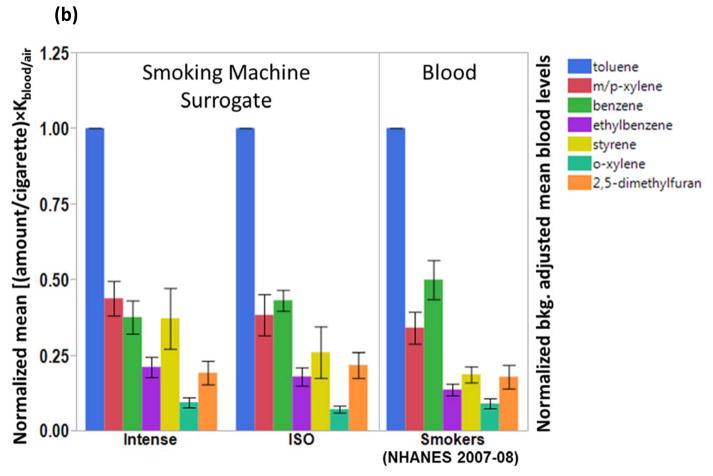
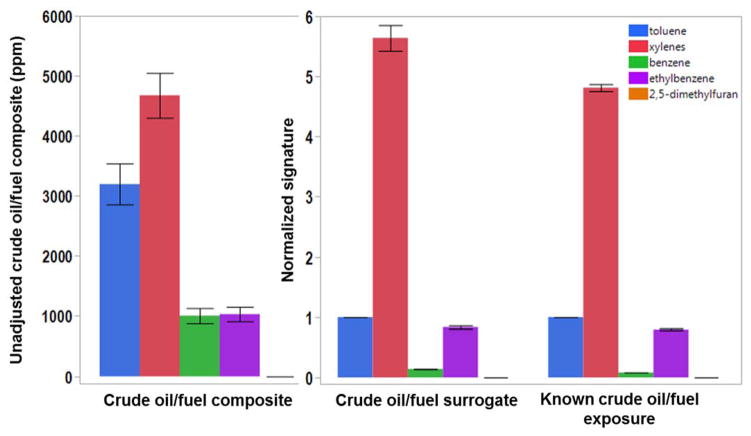
Description:Studies of exposure to petroleum (crude oil/fuel) often involve monitoring benzene, toluene, ethylbenzene, xylenes (BTEX), and styrene (BTEXS) because of their toxicity and gas-phase prevalence, where exposure is typically by inhalation. However, BTEXS levels in the general U.S. population are primarily from exposure to tobacco smoke, where smokers have blood levels on average up to eight times higher than nonsmokers. This work describes a method using partition theory and artificial neural network (ANN) pattern recognition to classify exposure source based on relative BTEXS and 2,5-dimethylfuran blood levels. A method using surrogate signatures to train the ANN was validated by comparing blood levels among cigarette smokers from the National Health and Nutrition Examination Survey (NHANES) with BTEXS and 2,5-dimethylfuran signatures derived from the smoke of machine-smoked cigarettes. Classification agreement for an ANN model trained with relative VOC levels was up to 99.8% for nonsmokers and 100.0% for smokers. As such, because there is limited blood level data on individuals exposed to crude oil/fuel, only surrogate signatures derived from crude oil and fuel were used for training the ANN. For the 2007-2008 NHANES data, the ANN model assigned 7 out of 1998 specimens (0.35%) and for the 2013-2014 NHANES data 12 out of 2906 specimens (0.41%) to the crude oil/fuel signature category.
-
Subjects:
-
Source:Environ Sci Technol. 52(1):308-316.
-
Pubmed ID:29216422
-
Pubmed Central ID:PMC5750095
-
Document Type:
-
Funding:
-
Volume:52
-
Issue:1
-
Collection(s):
-
Main Document Checksum:urn:sha256:7b964bffbb04b4f447e7ac198cd2d62b01b7c0779d4d8640ecaf5ba3376db296
-
Download URL:
-
File Type:
 [PDF
- 672.16 KB
]
[PDF
- 672.16 KB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access