Comparison of Machine Learning Classifiers for Influenza Detection from Emergency Department Free-text Reports
Supporting Files

-
12 2015
-
File Language:
English
Details
-
Alternative Title:J Biomed Inform
-
Personal Author:
-
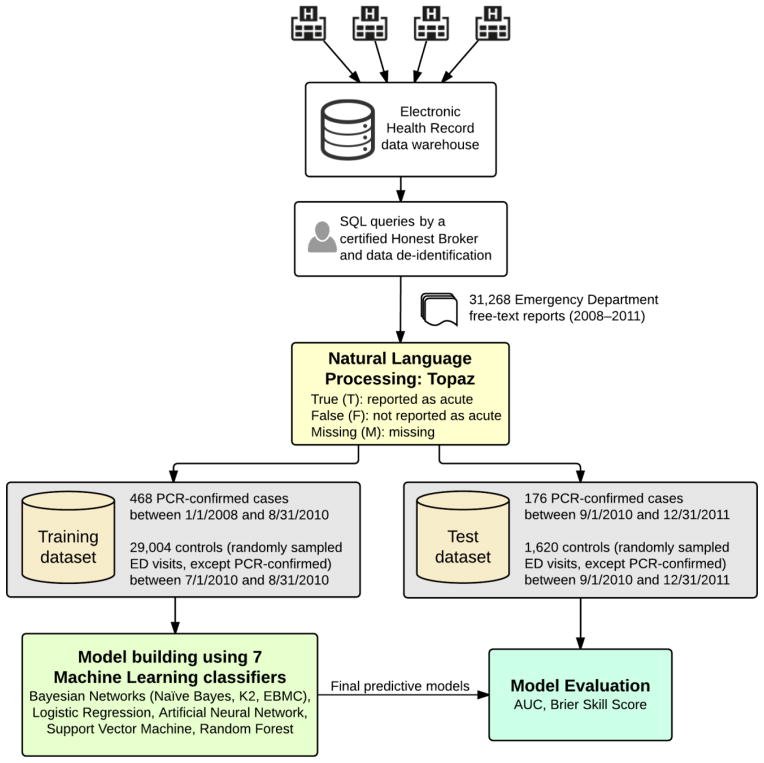
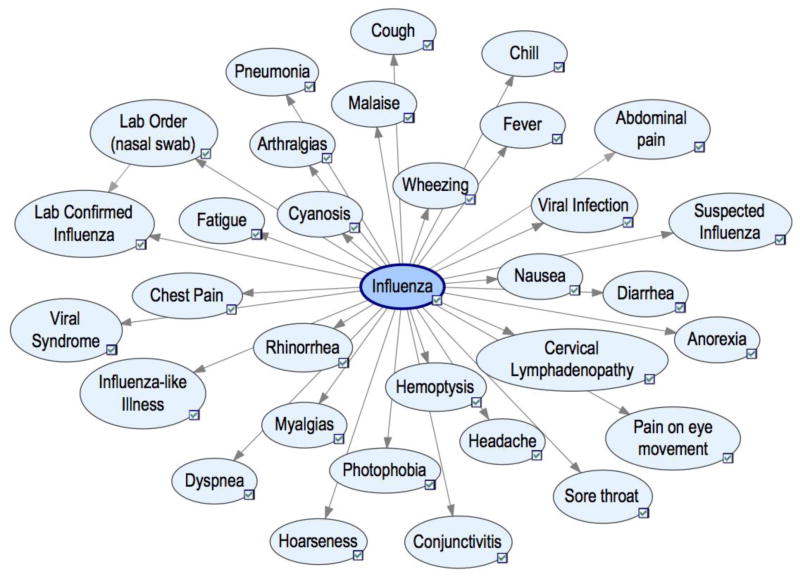
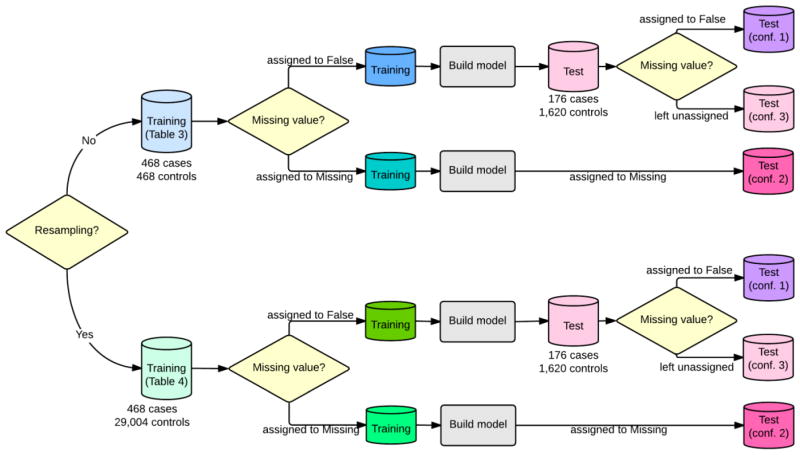
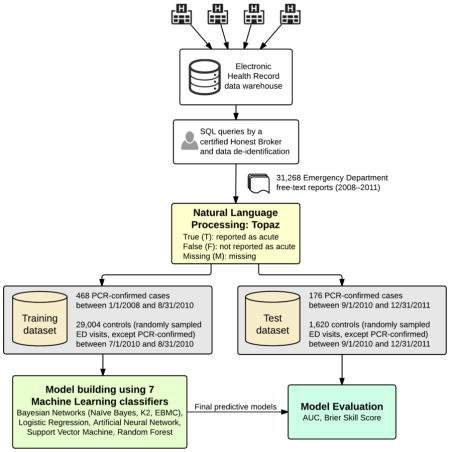
Description:Influenza is a yearly recurrent disease that has the potential to become a pandemic. An effective biosurveillance system is required for early detection of the disease. In our previous studies, we have shown that electronic Emergency Department (ED) free-text reports can be of value to improve influenza detection in real time. This paper studies seven machine learning (ML) classifiers for influenza detection, compares their diagnostic capabilities against an expert-built influenza Bayesian classifier, and evaluates different ways of handling missing clinical information from the free-text reports. We identified 31,268 ED reports from 4 hospitals between 2008 and 2011 to form two different datasets: training (468 cases, 29,004 controls), and test (176 cases and 1620 controls). We employed Topaz, a natural language processing (NLP) tool, to extract influenza-related findings and to encode them into one of three values: Acute, Non-acute, and Missing. Results show that all ML classifiers had areas under ROCs (AUC) ranging from 0.88 to 0.93, and performed significantly better than the expert-built Bayesian model. Missing clinical information marked as a value of missing (not missing at random) had a consistently improved performance among 3 (out of 4) ML classifiers when it was compared with the configuration of not assigning a value of missing (missing completely at random). The case/control ratios did not affect the classification performance given the large number of training cases. Our study demonstrates ED reports in conjunction with the use of ML and NLP with the handling of missing value information have a great potential for the detection of infectious diseases.
-
Subjects:
-
Keywords:
-
Source:J Biomed Inform. 58:60-69
-
Pubmed ID:26385375
-
Pubmed Central ID:PMC4684714
-
Document Type:
-
Funding:U38HK000063/HK/PHITPO CDC HHSUnited States/ ; P01HK000086/HK/PHITPO CDC HHSUnited States/ ; R01LM010020/LM/NLM NIH HHSUnited States/ ; U38 HK000063/HK/PHITPO CDC HHSUnited States/ ; R01 LM010020/LM/NLM NIH HHSUnited States/ ; R01LM011370/LM/NLM NIH HHSUnited States/ ; R01LM012095/LM/NLM NIH HHSUnited States/ ; P01 HK000086/HK/PHITPO CDC HHSUnited States/ ; R01 LM012095/LM/NLM NIH HHSUnited States/ ; R01 LM011370/LM/NLM NIH HHSUnited States/
-
Volume:58
-
Collection(s):
-
Main Document Checksum:urn:sha256:c2a12c075639ed6576259d979468db402b8003f150a8a4fc7a5be6b248480038
-
Download URL:
-
File Type:
 [PDF
- 1016.35 KB
]
[PDF
- 1016.35 KB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access