A UMLS-based spell checker for natural language processing in vaccine safety
Supporting Files
Public Domain

-
Feb 12 2007
-
File Language:
English
Details
-
Alternative Title:BMC Med Inform Decis Mak
-
Personal Author:
-
Description:Background
The Institute of Medicine has identified patient safety as a key goal for health care in the United States. Detecting vaccine adverse events is an important public health activity that contributes to patient safety. Reports about adverse events following immunization (AEFI) from surveillance systems contain free-text components that can be analyzed using natural language processing. To extract Unified Medical Language System (UMLS) concepts from free text and classify AEFI reports based on concepts they contain, we first needed to clean the text by expanding abbreviations and shortcuts and correcting spelling errors. Our objective in this paper was to create a UMLS-based spelling error correction tool as a first step in the natural language processing (NLP) pipeline for AEFI reports.
Methods
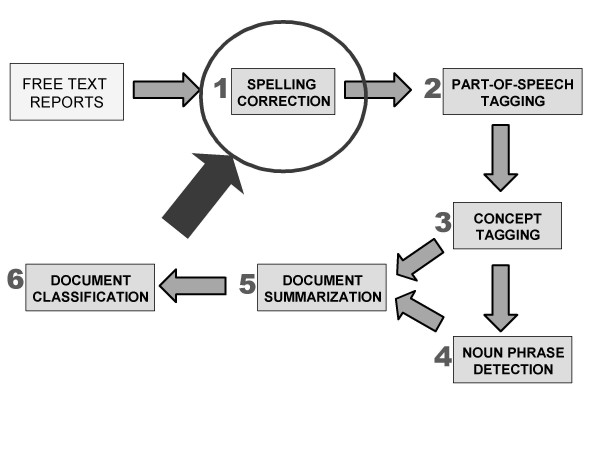
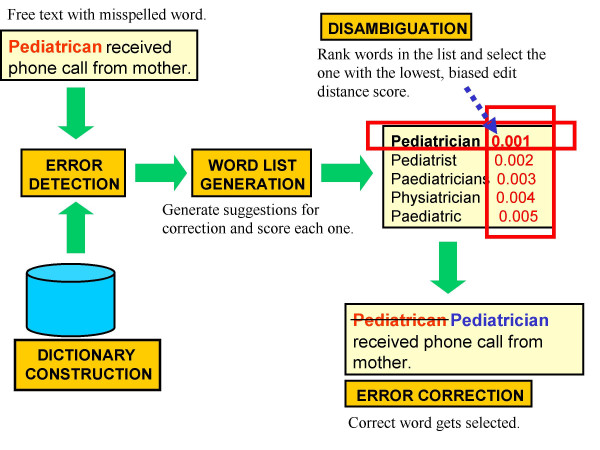
We developed spell checking algorithms using open source tools. We used de-identified AEFI surveillance reports to create free-text data sets for analysis. After expansion of abbreviated clinical terms and shortcuts, we performed spelling correction in four steps: (1) error detection, (2) word list generation, (3) word list disambiguation and (4) error correction. We then measured the performance of the resulting spell checker by comparing it to manual correction.
Results
We used 12,056 words to train the spell checker and tested its performance on 8,131 words. During testing, sensitivity, specificity, and positive predictive value (PPV) for the spell checker were 74% (95% CI: 74–75), 100% (95% CI: 100–100), and 47% (95% CI: 46%–48%), respectively.
Conclusion
We created a prototype spell checker that can be used to process AEFI reports. We used the UMLS Specialist Lexicon as the primary source of dictionary terms and the WordNet lexicon as a secondary source. We used the UMLS as a domain-specific source of dictionary terms to compare potentially misspelled words in the corpus. The prototype sensitivity was comparable to currently available tools, but the specificity was much superior. The slow processing speed may be improved by trimming it down to the most useful component algorithms. Other investigators may find the methods we developed useful for cleaning text using lexicons specific to their area of interest.
-
Subjects:
-
Source:BMC Med Inform Decis Mak. 2007; 7:3.
-
Document Type:
-
Volume:7
-
Collection(s):
-
Main Document Checksum:urn:sha-512:a4efbc0267b5cf1f36ae96a3cded257aac7c2213adf1f1e08cb9026dc59576ab98888ea321192a0634bf40ddbfcce7510fcee1d87c8b7d370e000fc34f890fd2
-
Download URL:
-
File Type:
 [PDF
- 519.14 KB
]
[PDF
- 519.14 KB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access