Coding Completeness and Quality of Relative Survival-Related Variables in the National Program of Cancer Registries Cancer Surveillance System 1995–2008
Supporting Files

-
2014
-
File Language:
English
Details
-
Alternative Title:J Registry Manag
-
Personal Author:
-
Description:Background
Calculating accurate estimates of cancer survival are important for various analyses of cancer patient care and prognosis. Current U.S. survival rates are estimated based on data from the National Cancer Institute’s (NCI’s) Surveillance, Epidemiology, and End Results (SEER) program, covering approximately 28% of the U.S. population. The National Program of Cancer Registries (NPCR) covers about 96% of the U.S. population. Using a population-based database with greater U.S. population coverage to calculate survival rates at the national, state, and regional levels can further enhance the effective monitoring of cancer patient care and prognosis in the U.S. The first step is to establish the coding completeness and coding quality of the NPCR data needed for calculating survival rates and conducting related validation analyses.
Methods
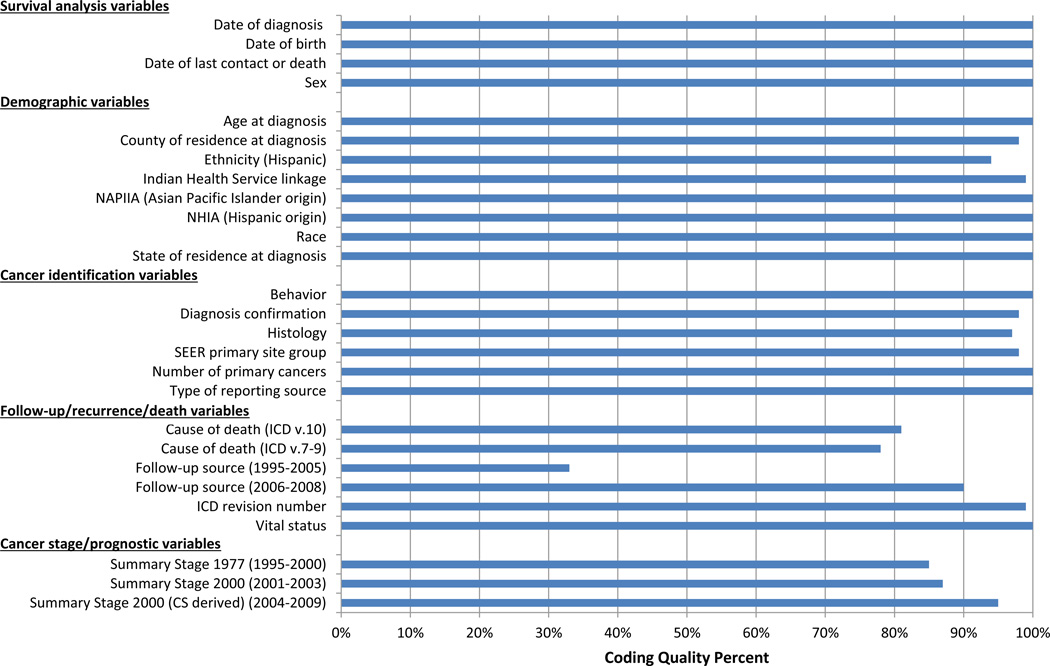
Using data from the NPCR-Cancer Surveillance System (CSS) from 1995 through 2008, we assessed coding completeness and quality on 26 data elements that are needed to calculate cancer relative survival estimates and conduct related analyses. Data elements evaluated consisted of demographic, follow-up, prognostic, and cancer identification variables. Analyses showing trends of these variables by diagnostic year, state of residence at diagnosis, and cancer site were performed.
Results
Mean overall percent coding completeness by each NPCR central cancer registry averaged across all data elements and diagnosis years ranged from 92.3% to 100%. Results showing the mean percent coding completeness for the relative survival-related variables in NPCR data are presented. All data elements but one have a mean coding completeness greater than 90% as was the mean completeness by data item group type. Statistically significant differences in coding completeness were found in the ICD revision number, cause of death, vital status, and date of last contact variables when comparing diagnosis years. The majority of data items had a coding quality greater than 90%, with exceptions found in cause of death, follow-up source, and the Surveillance, Epidemiology, and End Results (SEER) Summary Stage 1977, and SEER Summary Stage 2000.
Conclusion
Percent coding completeness and quality are very high for variables in the NPCR-CSS that are covariates to calculating relative survival. NPCR provides the opportunity to calculate relative survival that may be more generalizable to the U.S. population.
-
Subjects:
-
Source:J Registry Manag. 41(2):65-97.
-
Pubmed ID:25153011
-
Pubmed Central ID:PMC4369759
-
Document Type:
-
Funding:
-
Name as Subject:
-
Place as Subject:
-
Volume:41
-
Issue:2
-
Collection(s):
-
Main Document Checksum:urn:sha256:d8ecfbe06e3c7ca51aebe9bb7bdfab3ab8104eed185c3af95d7a359d3dcad5d7
-
Download URL:
-
File Type:
 [PDF
- 630.16 KB
]
[PDF
- 630.16 KB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access