Using Machine Learning to Evaluate Coal Geochemical Data with Respect to Dynamic Failures
Supporting Files

-
6 09 2023
File Language:
English
Details
-
Alternative Title:Minerals (Basel)
-
Personal Author:
-
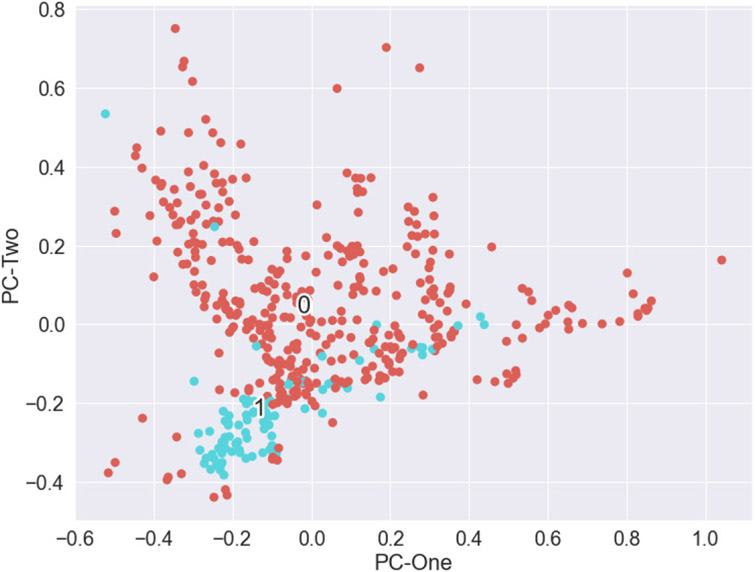
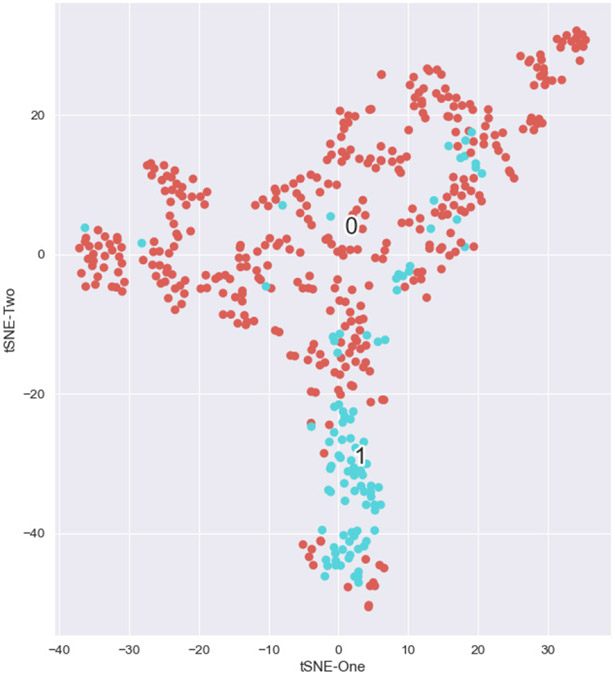
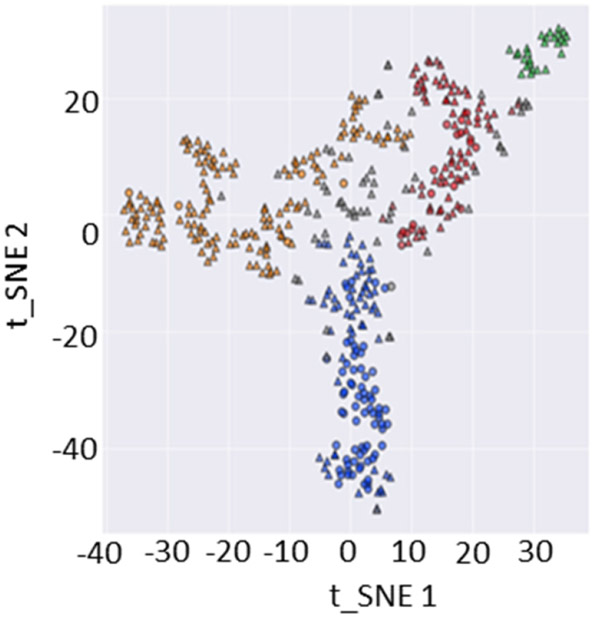
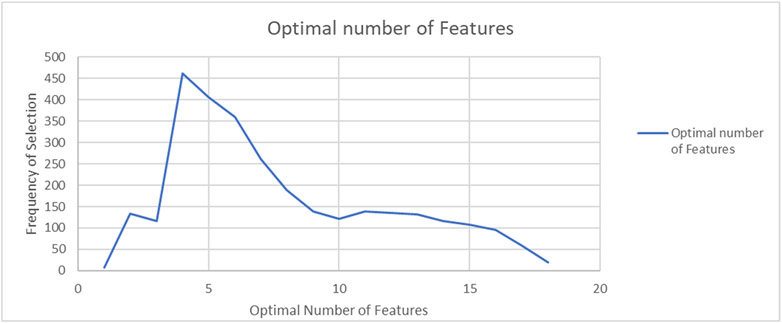
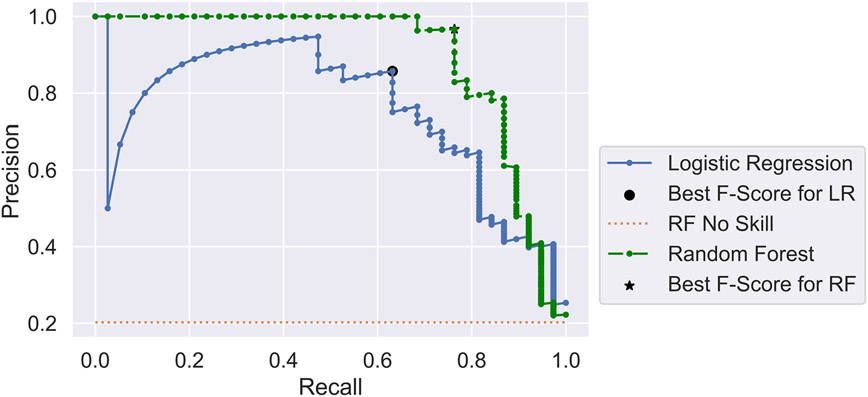
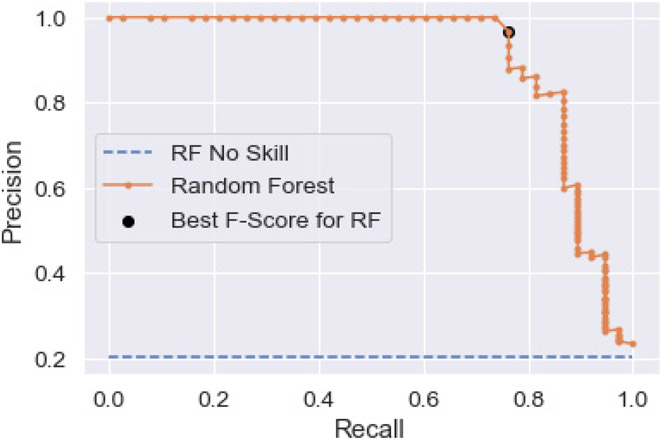
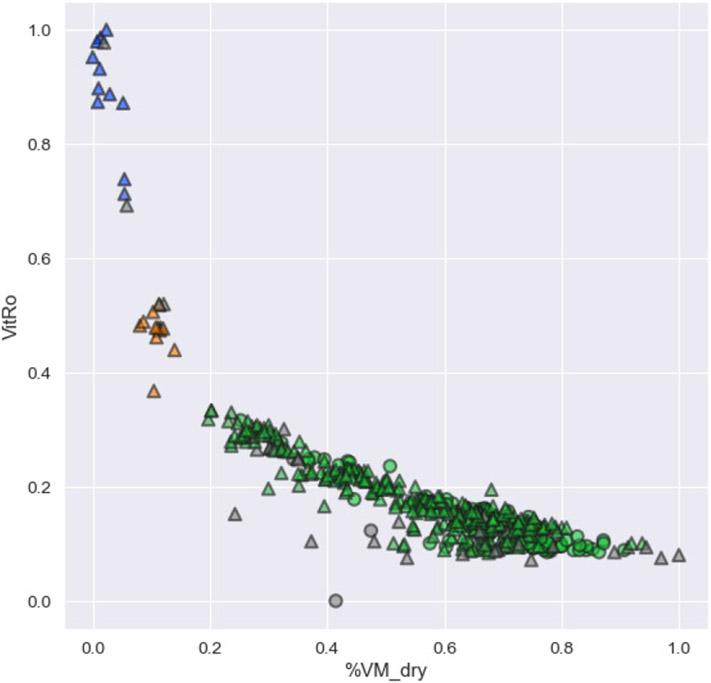
Description:Dynamic failure events have occurred in the underground coal mining industry since its inception. Recent NIOSH research has identified geochemical markers that correlate with in situ reportable dynamic event occurrence, although the causes behind this correlative relationship remain unclear. In this study, NIOSH researchers conducted machine learning analysis to examine whether a model could be constructed to assess the probability of dynamic failure occurrence based on geochemical and petrographic data. Linear regression, random forest, dimensionality reduction, and cluster analyses were applied to a catalog of dynamic failure and control data from the Pennsylvania Coal Sample Databank, cross-referenced with accident data from the Mine Safety and Health Administration (MSHA). Analyses determined that 7 of the 18 geochemical parameters that were examined had the biggest impact on model performance. Classifications based on logistic regression and random forest models attained precision values of 85.7% and 96.7%, respectively. Dimensionality reduction was used to explore patterns and groupings in the data and to search for relationships between compositional parameters. Cluster analyses were performed to determine if an algorithm could find clusters with given class memberships and to what extent misclassifications of dynamic failure status occurred. Cluster analysis using a hierarchal clustering algorithm after dimensionality reduction resulted in four clusters, with one relatively distinct dynamic failure cluster, and three clusters mostly consisting of control group members but with a small number of dynamic failure members.
-
Keywords:
-
Source:Minerals (Basel). 13(6):808
-
Pubmed ID:39010938
-
Pubmed Central ID:PMC11249035
-
Document Type:
-
Funding:
-
Volume:13
-
Issue:6
-
Collection(s):
-
Main Document Checksum:urn:sha-512:d97964ac57dc3b283683ff759783af3b1881f388e26e4c29e042ec31e7081471da4c38c603a57fc5b18239738da2f967fc8b041988dc06c41b8e3ae4ce2b8d3e
-
Download URL:
-
File Type:
 [PDF
- 937.15 KB
]
[PDF
- 937.15 KB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access