Accelerated training of bootstrap aggregation-based deep information extraction systems from cancer pathology reports
Supporting Files

-
October 2020
-
File Language:
English
Details
-
Alternative Title:J Biomed Inform
-
Personal Author:
-
Description:Objective:
In machine learning, it is evident that the classification of the task performance increases if bootstrap aggregation (bagging) is applied. However, the bagging of deep neural networks takes tremendous amounts of computational resources and training time. The research question that we aimed to answer in this research is whether we could achieve higher task performance scores and accelerate the training by dividing a problem into sub-problems.
Materials and Methods:
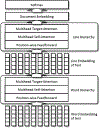
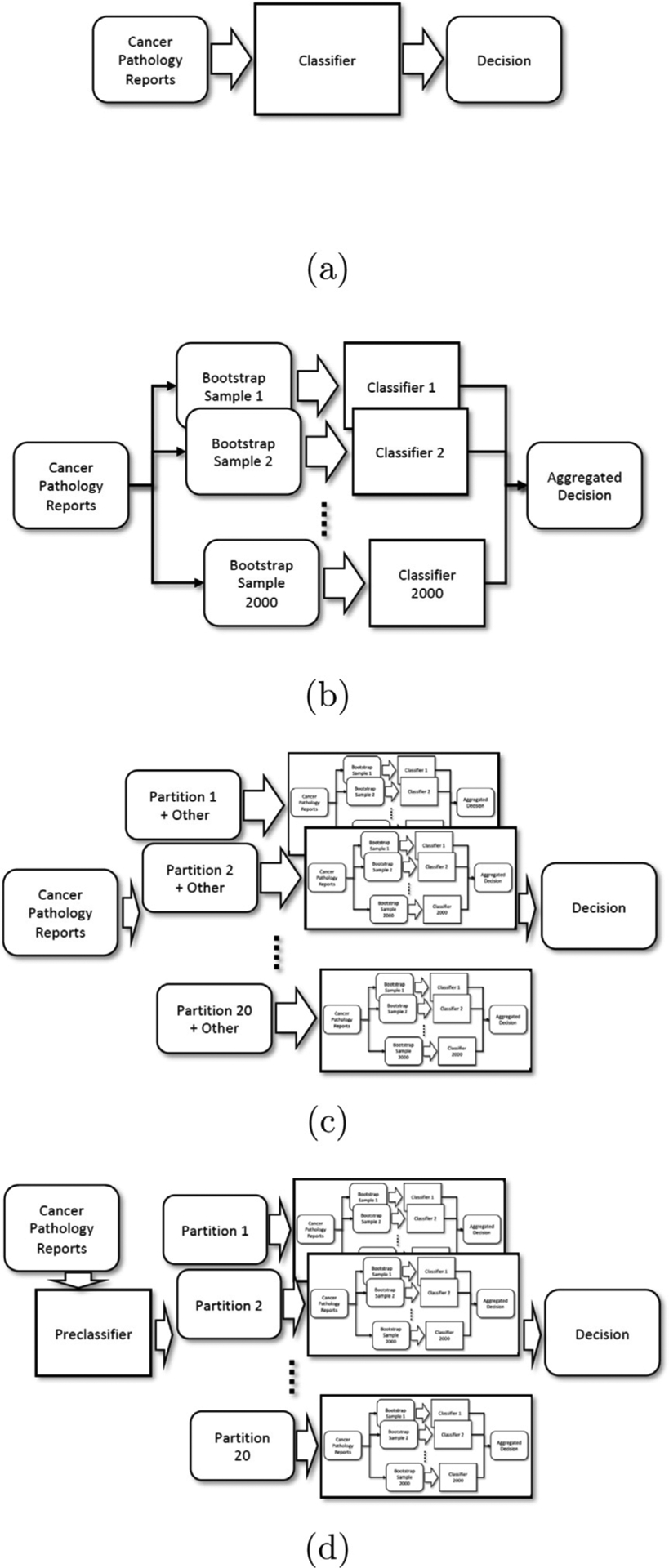
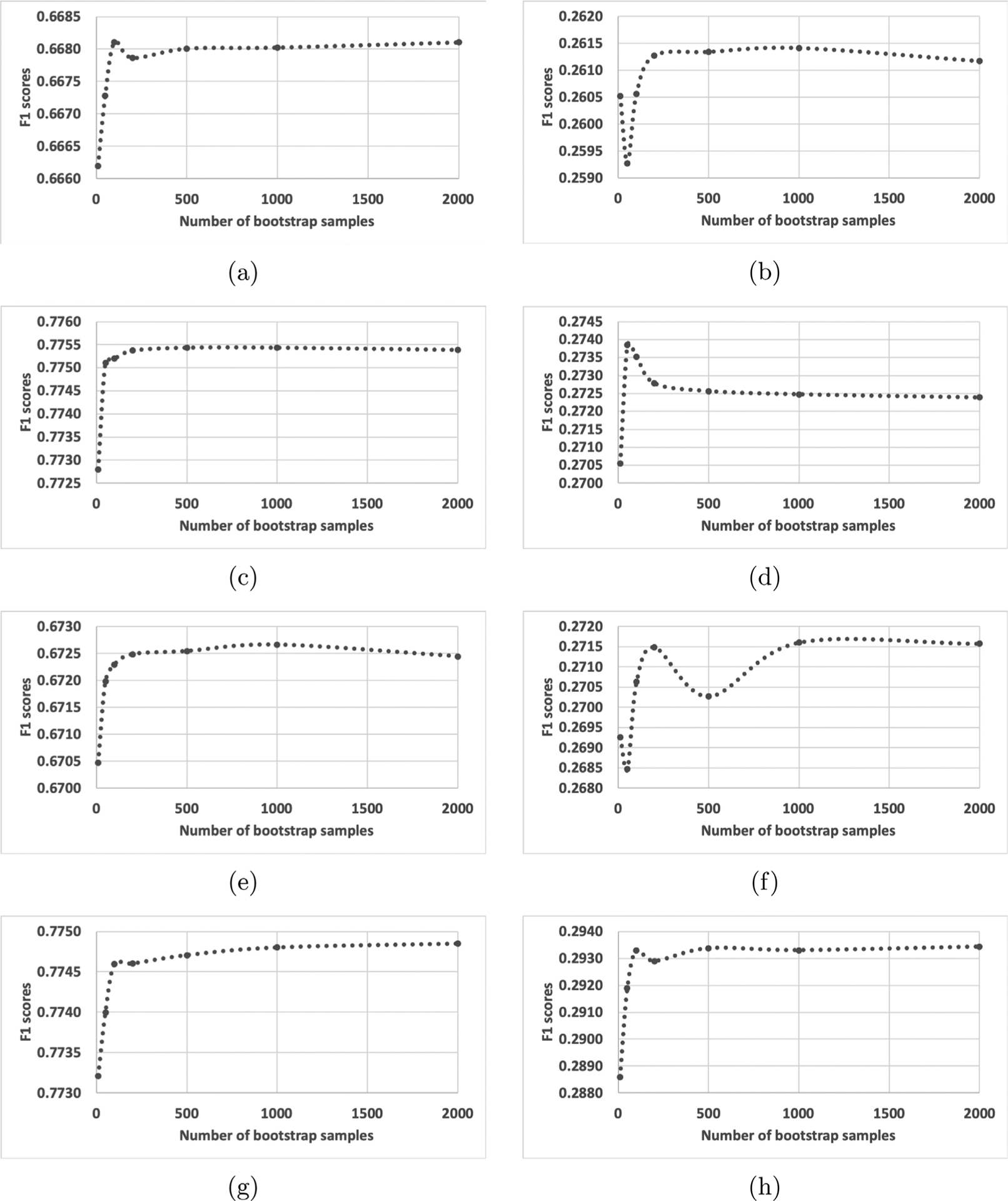
The data used in this study consist of free text from electronic cancer pathology reports. We applied bagging and partitioned data training using Multi-Task Convolutional Neural Network (MT-CNN) and Multi-Task Hierarchical Convolutional Attention Network (MT-HCAN) classifiers. We split a big problem into 20 sub-problems, resampled the training cases 2,000 times, and trained the deep learning model for each bootstrap sample and each sub-problem—thus, generating up to 40,000 models. We performed the training of many models concurrently in a high-performance computing environment at Oak Ridge National Laboratory (ORNL).
Results:
We demonstrated that aggregation of the models improves task performance compared with the single-model approach, which is consistent with other research studies; and we demonstrated that the two proposed partitioned bagging methods achieved higher classification accuracy scores on four tasks. Notably, the improvements were significant for the extraction of cancer histology data, which had more than 500 class labels in the task; these results show that data partition may alleviate the complexity of the task. On the contrary, the methods did not achieve superior scores for the tasks of site and subsite classification. Intrinsically, since data partitioning was based on the primary cancer site, the accuracy depended on the determination of the partitions, which needs further investigation and improvement.
Conclusion:
Results in this research demonstrate that 1. The data partitioning and bagging strategy achieved higher performance scores. 2. We achieved faster training leveraged by the high-performance Summit supercomputer at ORNL.
-
Subjects:
-
Source:J Biomed Inform. 110:103564
-
Pubmed ID:32919043
-
Pubmed Central ID:PMC8276580
-
Document Type:
-
Funding:HHSN261201800013C/CA/NCI NIH HHSUnited States/ ; HHSN261201800016C/CA/NCI NIH HHSUnited States/ ; U58 DP003907/DP/NCCDPHP CDC HHSUnited States/ ; HHSN261201800007C/CA/NCI NIH HHSUnited States/ ; P30 CA177558/CA/NCI NIH HHSUnited States/ ; HHSN261201300021C/CA/NCI NIH HHSUnited States/ ; HHSN261201800013I/CA/NCI NIH HHSUnited States/ ; P30 CA042014/CA/NCI NIH HHSUnited States/
-
Volume:110
-
Collection(s):
-
Main Document Checksum:urn:sha256:8a9e6503a56488b7a5e6a18a8f17ad1c7ae667d9020b62dbcb7570e10f560e1b
-
Download URL:
-
File Type:
 [PDF
- 699.06 KB
]
[PDF
- 699.06 KB
]
Supporting Files

File Language:
English
ON THIS PAGE

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CDC STACKS serves as an archival repository of CDC-published products including
scientific findings,
journal articles, guidelines, recommendations, or other public health information authored or
co-authored by CDC or funded partners.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
As a repository, CDC STACKS retains documents in their original published format to ensure public access to scientific information.
You May Also Like
COLLECTION
CDC Public Access