i
Grouping of variables to facilitate statistical disclosure limitation methods in multivariate data sets
-
Jan 2018
Source: Priv Stat Databases. ? -
Alternative Title:Priv Stat Databases
-
Personal Author:
-
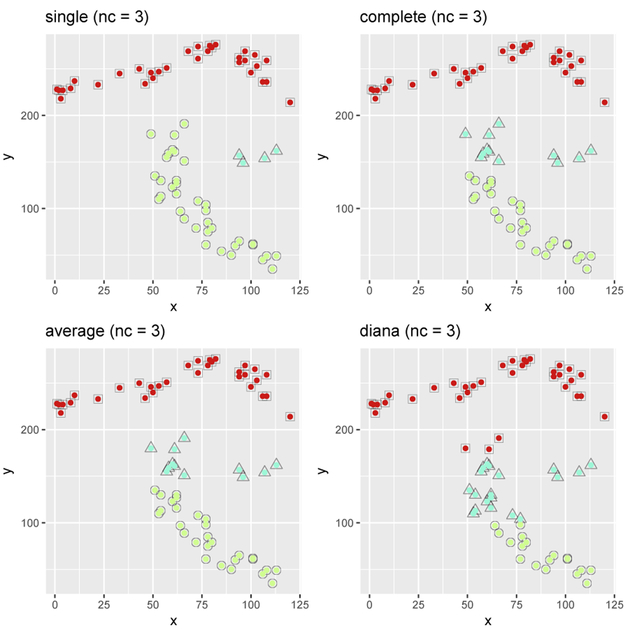
Description:Data sets that are subject to Statistical Disclosure Limitation (SDL) often have many variables of different types that need to be altered for disclosure limitation. To produce a good quality public data set, the data protector needs to account for the relationships between the variables. Hence, ideally SDL methods should not be univariate, that is, treating each variable independently of others, but multivariate, handling many variables at the same time. However, if a data set has many variables, as most government survey data do, the task of developing and implementing a multivariate approach for SDL becomes difficult. In this paper we propose a pre-masking data processing procedure which consists of clustering the variables of high dimensional data sets, so that different groups of variables can be masked independently, thus reducing the complexity of SDL. We consider different hierarchical clustering methods, including our version of hierarchical clustering algorithm, that we call |, and outline how the data protector can define an appropriate number of clusters for these methods. We implemented and applied these methods to two genuine multivariate data sets. The results of the experiments show that | has a potential to solve this problem efficiently. The success of the method, however, depends on the correlation structure of the data. For the data sets where most of the variables are correlated, clustering of variables and subsequent independent application of SDL methods to different clusters may lead to attenuated correlation in the masked data, even for efficient clustering methods. Thereby, the proposed approach is a trade-off between the computational complexity of multivariate SDL methods and data utility loss due to independent treatment of different clusters by SDL methods. | Statistical disclosure limitation (SDL), hierarchical clustering, dimensionality reduction.
-
Subjects:
-
Source:
-
Pubmed ID:32337514
-
Pubmed Central ID:PMC7182379
-
Document Type:
-
Collection(s):
-
Main Document Checksum:
-
Download URL:
-
File Type:
 [PDF-480.21 KB]
[PDF-480.21 KB]
Details:
Supporting Files


More +


 Email
CDC-INFO
Email
CDC-INFO