i
Random KNN feature selection - a fast and stable alternative to Random Forests
-
Nov 18 2011
Source: BMC Bioinformatics. 2011; 12:450.
 [PDF-372.80 KB]
[PDF-372.80 KB]
Details:
-
Alternative Title:BMC Bioinformatics
-
Personal Author:
-
Description:Background
Successfully modeling high-dimensional data involving thousands of variables is challenging. This is especially true for gene expression profiling experiments, given the large number of genes involved and the small number of samples available. Random Forests (RF) is a popular and widely used approach to feature selection for such "small n, large p problems." However, Random Forests suffers from instability, especially in the presence of noisy and/or unbalanced inputs.
Results
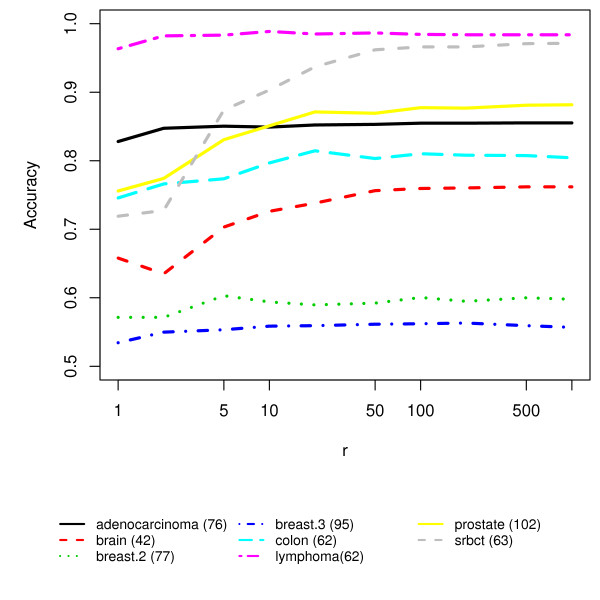
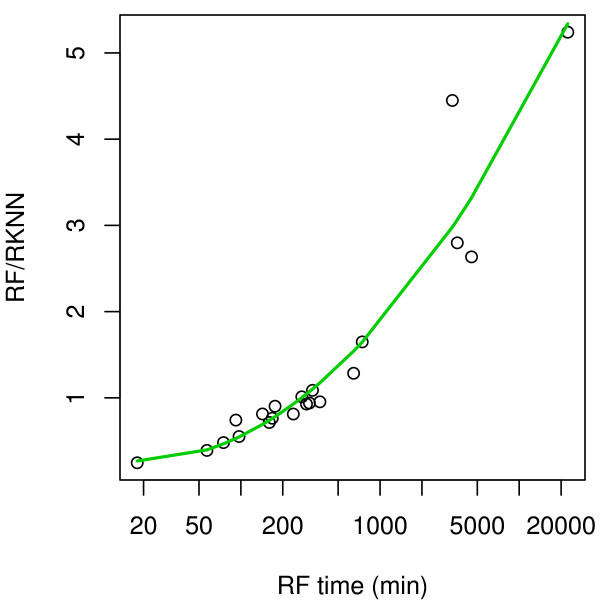
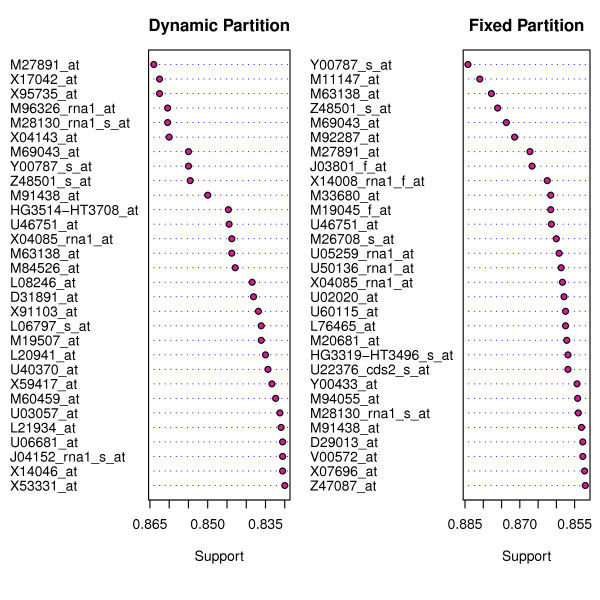
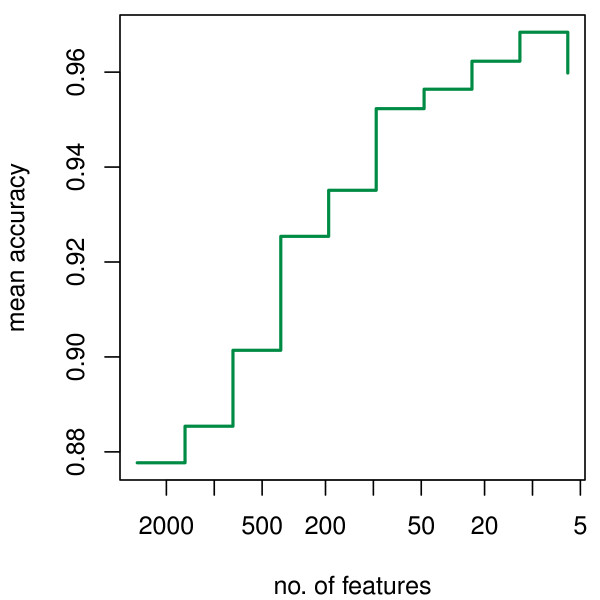
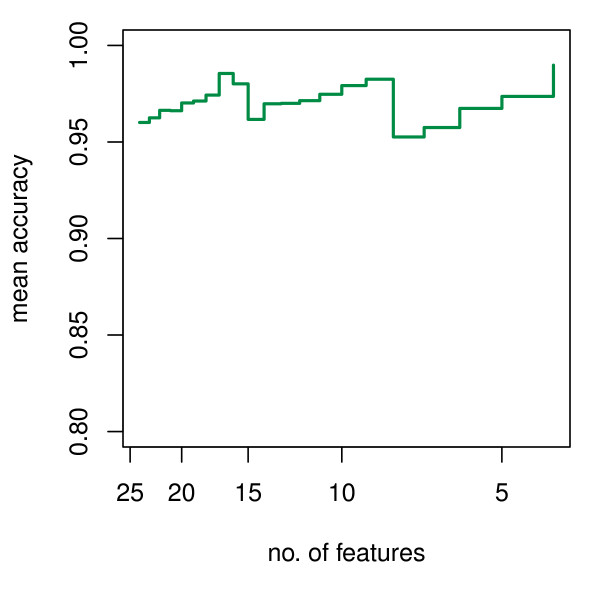
We present RKNN-FS, an innovative feature selection procedure for "small n, large p problems." RKNN-FS is based on Random KNN (RKNN), a novel generalization of traditional nearest-neighbor modeling. RKNN consists of an ensemble of base k-nearest neighbor models, each constructed from a random subset of the input variables. To rank the importance of the variables, we define a criterion on the RKNN framework, using the notion of support. A two-stage backward model selection method is then developed based on this criterion. Empirical results on microarray data sets with thousands of variables and relatively few samples show that RKNN-FS is an effective feature selection approach for high-dimensional data. RKNN is similar to Random Forests in terms of classification accuracy without feature selection. However, RKNN provides much better classification accuracy than RF when each method incorporates a feature-selection step. Our results show that RKNN is significantly more stable and more robust than Random Forests for feature selection when the input data are noisy and/or unbalanced. Further, RKNN-FS is much faster than the Random Forests feature selection method (RF-FS), especially for large scale problems, involving thousands of variables and multiple classes.
Conclusions
Given the superiority of Random KNN in classification performance when compared with Random Forests, RKNN-FS's simplicity and ease of implementation, and its superiority in speed and stability, we propose RKNN-FS as a faster and more stable alternative to Random Forests in classification problems involving feature selection for high-dimensional datasets.
-
Subjects:
-
Document Type:
-
Collection(s):
-
Main Document Checksum:
-
Download URL:
-
File Type:
Supporting Files
-

gif 
jpeg 
gif 
jpeg 
gif 
jpeg 
txt
txt 
gif 
jpeg 
gif 
jpeg 
gif 
jpeg 
gif 
jpeg




More +


 Email
CDC-INFO
Email
CDC-INFO