i
Natural language generation for electronic health records
-
November 19 2018
Source: NPJ Digit Med. 1:63
 [PDF-171.81 KB]
[PDF-171.81 KB]
Details:
-
Alternative Title:NPJ Digit Med
-
Personal Author:
-
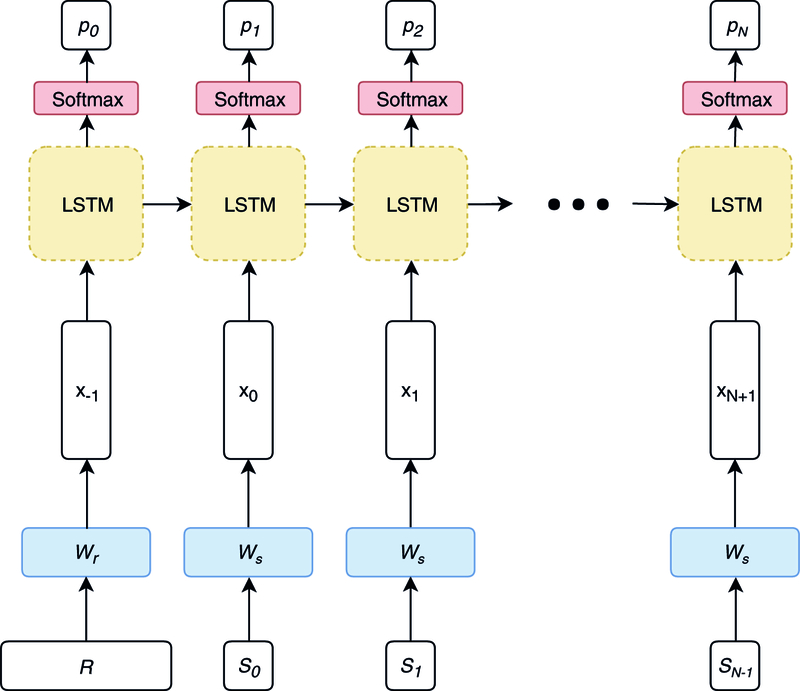
Description:One broad goal of biomedical informatics is to generate fully-synthetic, faithfully representative electronic health records (EHRs) to facilitate data sharing between healthcare providers and researchers and promote methodological research. A variety of methods existing for generating synthetic EHRs, but they are not capable of generating unstructured text, like emergency department (ED) chief complaints, history of present illness, or progress notes. Here, we use the encoder-decoder model, a deep learning algorithm that features in many contemporary machine translation systems, to generate synthetic chief complaints from discrete variables in EHRs, like age group, gender, and discharge diagnosis. After being trained end-to-end on authentic records, the model can generate realistic chief complaint text that appears to preserve the epidemiological information encoded in the original record-sentence pairs. As a side effect of the model's optimization goal, these synthetic chief complaints are also free of relatively uncommon abbreviation and misspellings, and they include none of the personally identifiable information (PII) that was in the training data, suggesting that this model may be used to support the de-identification of text in EHRs. When combined with algorithms like generative adversarial networks (GANs), our model could be used to generate fully-synthetic EHRs, allowing healthcare providers to share faithful representations of multimodal medical data without compromising patient privacy. This is an important advance that we hope will facilitate the development of machine-learning methods for clinical decision support, disease surveillance, and other data-hungry applications in biomedical informatics.
-
Subjects:
-
Source:
-
Pubmed ID:30687797
-
Pubmed Central ID:PMC6345174
-
Document Type:
-
Collection(s):
-
Main Document Checksum:
-
Download URL:
-
File Type:
Supporting Files


More +


 Email
CDC-INFO
Email
CDC-INFO