i
Modeling the probability distribution of positional errors incurred by residential address geocoding
-
Jan 10 2007
Source: Int J Health Geogr. 2007; 6:1. -
Alternative Title:Int J Health Geogr
-
Personal Author:
-
Description:Background
The assignment of a point-level geocode to subjects' residences is an important data assimilation component of many geographic public health studies. Often, these assignments are made by a method known as automated geocoding, which attempts to match each subject's address to an address-ranged street segment georeferenced within a streetline database and then interpolate the position of the address along that segment. Unfortunately, this process results in positional errors. Our study sought to model the probability distribution of positional errors associated with automated geocoding and E911 geocoding.
Results
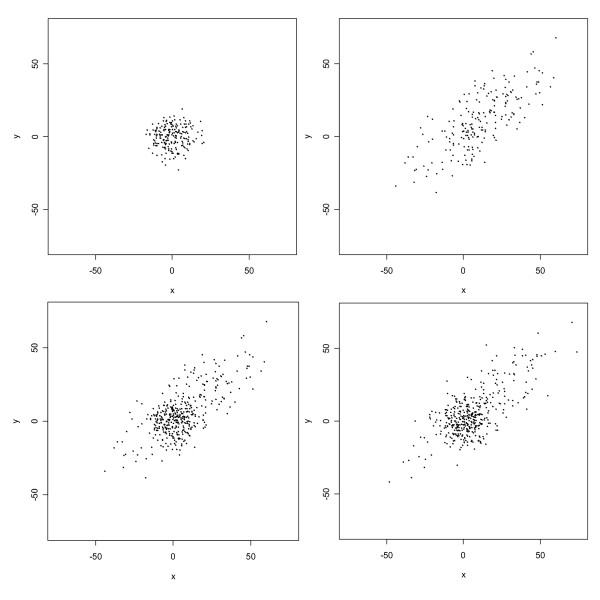
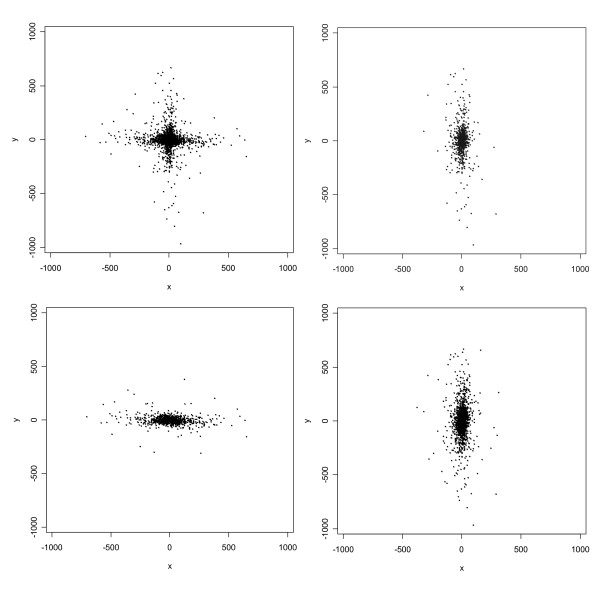
Positional errors were determined for 1423 rural addresses in Carroll County, Iowa as the vector difference between each 100%-matched automated geocode and its true location as determined by orthophoto and parcel information. Errors were also determined for 1449 60%-matched geocodes and 2354 E911 geocodes. Huge (> 15 km) outliers occurred among the 60%-matched geocoding errors; outliers occurred for the other two types of geocoding errors also but were much smaller. E911 geocoding was more accurate (median error length = 44 m) than 100%-matched automated geocoding (median error length = 168 m). The empirical distributions of positional errors associated with 100%-matched automated geocoding and E911 geocoding exhibited a distinctive Greek-cross shape and had many other interesting features that were not capable of being fitted adequately by a single bivariate normal or t distribution. However, mixtures of t distributions with two or three components fit the errors very well.
Conclusion
Mixtures of bivariate t distributions with few components appear to be flexible enough to fit many positional error datasets associated with geocoding, yet parsimonious enough to be feasible for nascent applications of measurement-error methodology to spatial epidemiology.
-
Subjects:
-
Source:
-
Document Type:
-
Place as Subject:
-
Collection(s):
-
Main Document Checksum:
-
Download URL:
-
File Type:
-

gif 
jpeg 
txt
txt 
gif 
jpeg 
gif 
jpeg 
gif 
jpeg 
gif 
jpeg
 [PDF-1.38 MB]
[PDF-1.38 MB]
Details:
Supporting Files




More +


 Email
CDC-INFO
Email
CDC-INFO